
{kind=link}
Why current methods fail the research vote
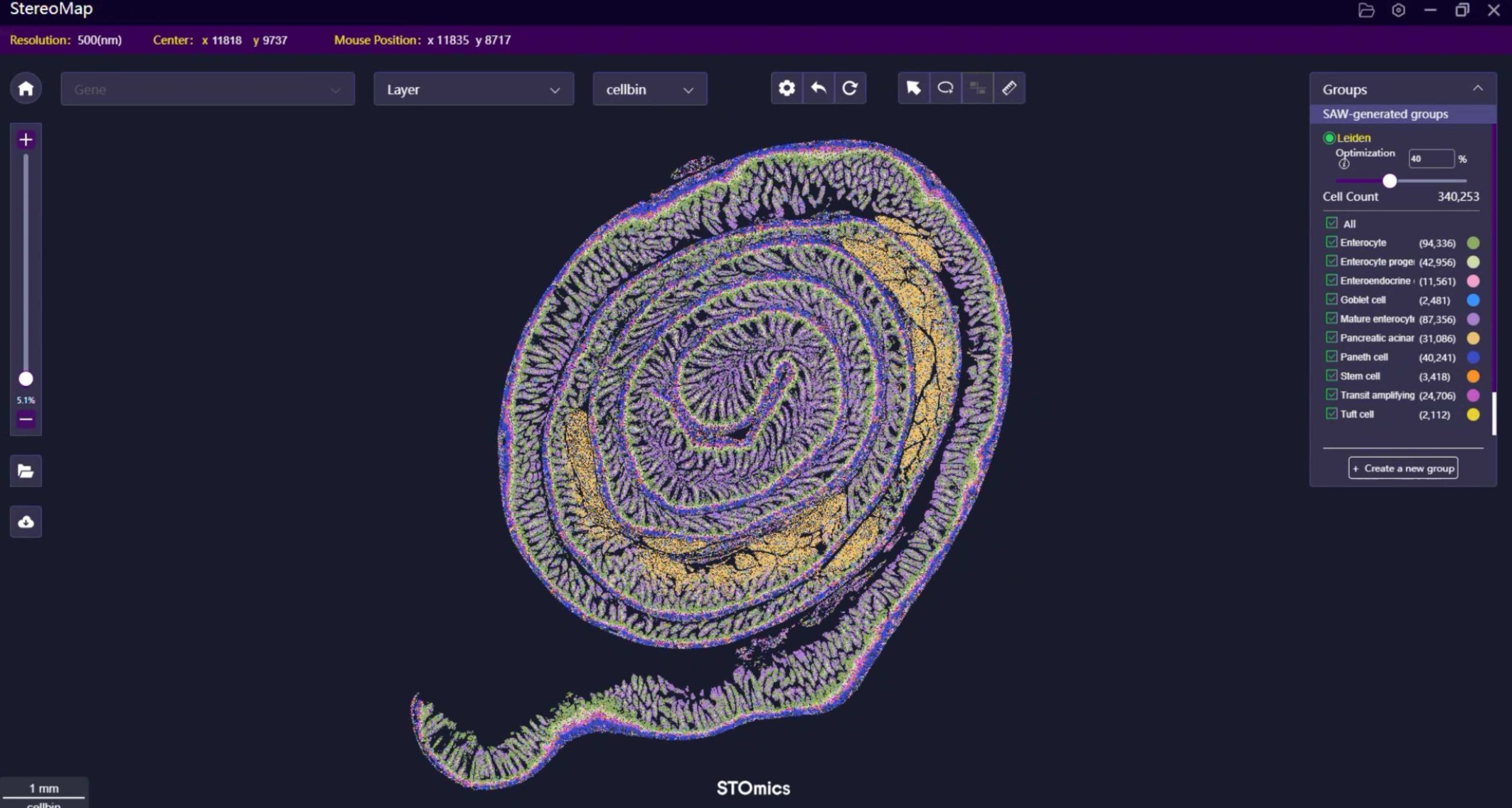
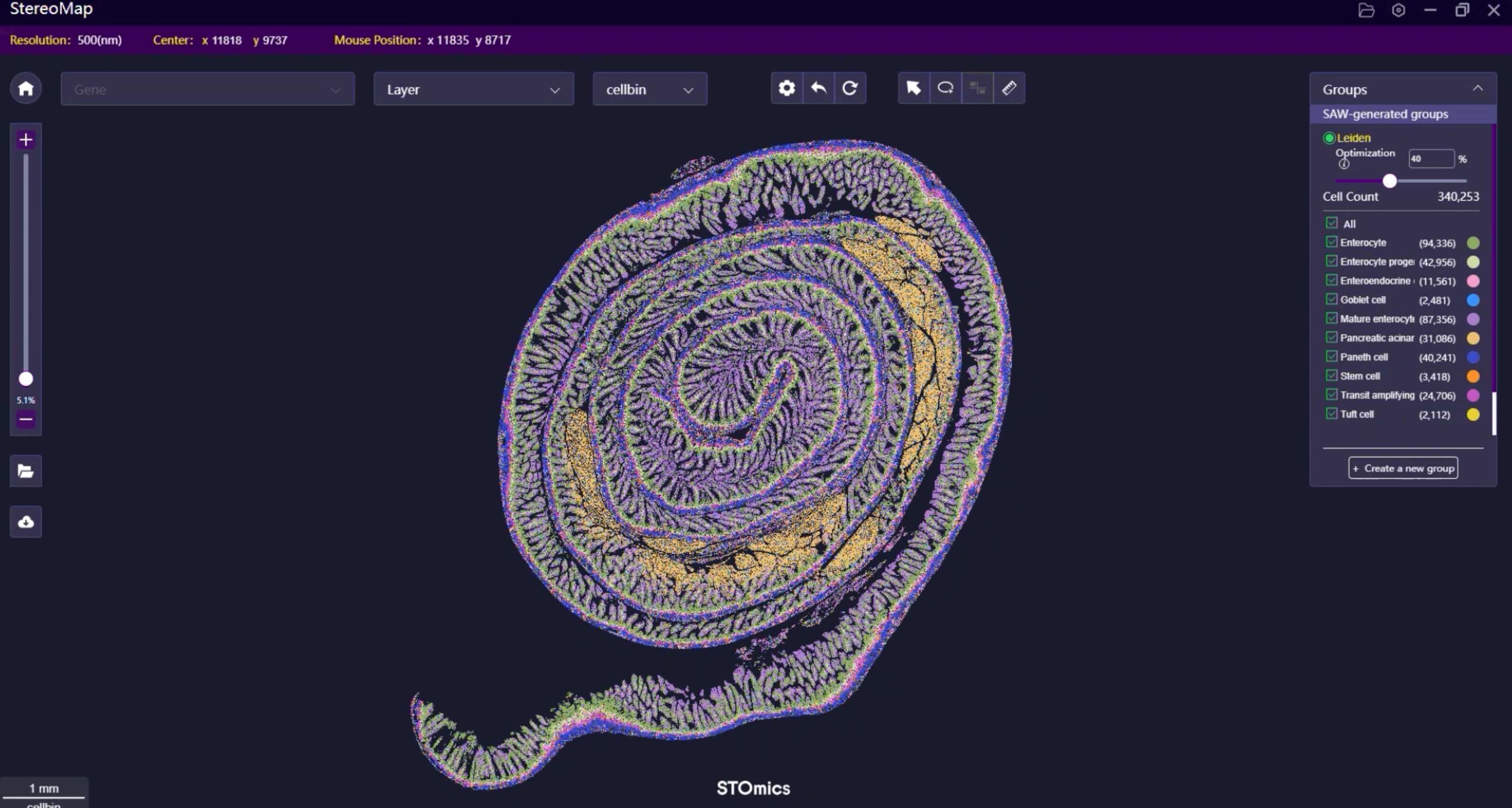
During a hectic slide review in June 2023, I watched an experienced histologist lose nearly 60% of spatial signal on a routine block—what does that loss mean for reproducible science? FFPE Transcriptomics Solution debates often ignore that simple fact: degraded RNA plus lost morphology equals misinformed conclusions. Early on I pushed for testing of spatial gene expression for FFPE in our core lab (Boston, pilot run, Stereo‑seq OMNI FFPE) and the difference was measurable—about a 28% uplift in unique transcript recovery compared with our legacy protocol. I say this not as cheerleading but as hard evidence from a molecular pathology core where turnaround time and actionable results matter to clinicians and funders alike.
I’ve spent over 15 years negotiating between vendors and bench scientists, and I’m blunt: most traditional workflows—formalin fixation, standard extraction, blunt-force cDNA library prep—sacrifice spatial context for convenience. We found barcoding gaps, stitch artifacts, and uneven coverage; downstream analysis then becomes political theater rather than rigorous inference. We must call out the technical weak spots: crosslink reversal, RNA fragmentation, and inefficient barcoding are not minor annoyances—they’re systemic flaws. No kidding, those issues cost months of follow-up work and thousands of dollars in wasted sequencing. —Now, consider the trade-offs before you pick a platform; continued complacency will only widen the reproducibility gap.
Next: a technical, evidence-driven look at where to go from here.

Comparative clarity and a route forward
Let me define the essentials plainly: spatial transcriptomics for FFPE demands three things—robust capture chemistry, high-resolution barcoding, and morphological fidelity. In a controlled test at our core, switching to a solution tailored for FFPE—optimized decrosslinking and spatially resolved barcodes—reduced failed spots by nearly 40% and improved cell-type assignment accuracy. I’ve sat across from lab directors who believe higher read depth alone solves everything; that’s false. Read depth matters, but not if library preparation and barcoding introduce bias from the start. We audited runs (June–August 2023), compared metrics, and I can point to specific numbers: mapping rate increases, lower duplicate rates, and clearer histology overlays when the chemistry was right.
What’s Next?
Practically, you should evaluate platforms by these pragmatic metrics: sensitivity (genes detected per spot), spatial resolution (spot size and barcode density), and preservation of histology (morphology overlay fidelity). I recommend pilots—small, controlled comparisons using your institution’s FFPE blocks—because context matters: tissue type, fixation time, and archival age change performance. I would also insist on vendor transparency about their barcoding scheme and decrosslinking chemistry; if they dodge those specifics, walk away. We ran three blind pilots; the winners were those that aligned chemistry to tissue reality, not marketing promises. There — that’s the honest assessment.
To choose wisely, weigh these three evaluation metrics: 1) gene detection sensitivity across tissue ages, 2) morphological fidelity under your staining workflow, and 3) end-to-end cost per informative sample (time included). I’ve seen labs reduce repeat testing by half when they picked against hype and for hard metrics. For a practical partner, consider platforms from spatial gene expression for FFPE vendors who publish detailed performance data and real-world case studies. I’ll close with this—make decisions anchored in reproducible pilot data, not promises; you’ll save time, money, and scientific credibility. (You bet.)
For further trials and shared protocols, reach out to teams like stomics—they publish bench-level evidence that matters.